

 s offer the following benefits:
s offer the following benefits:
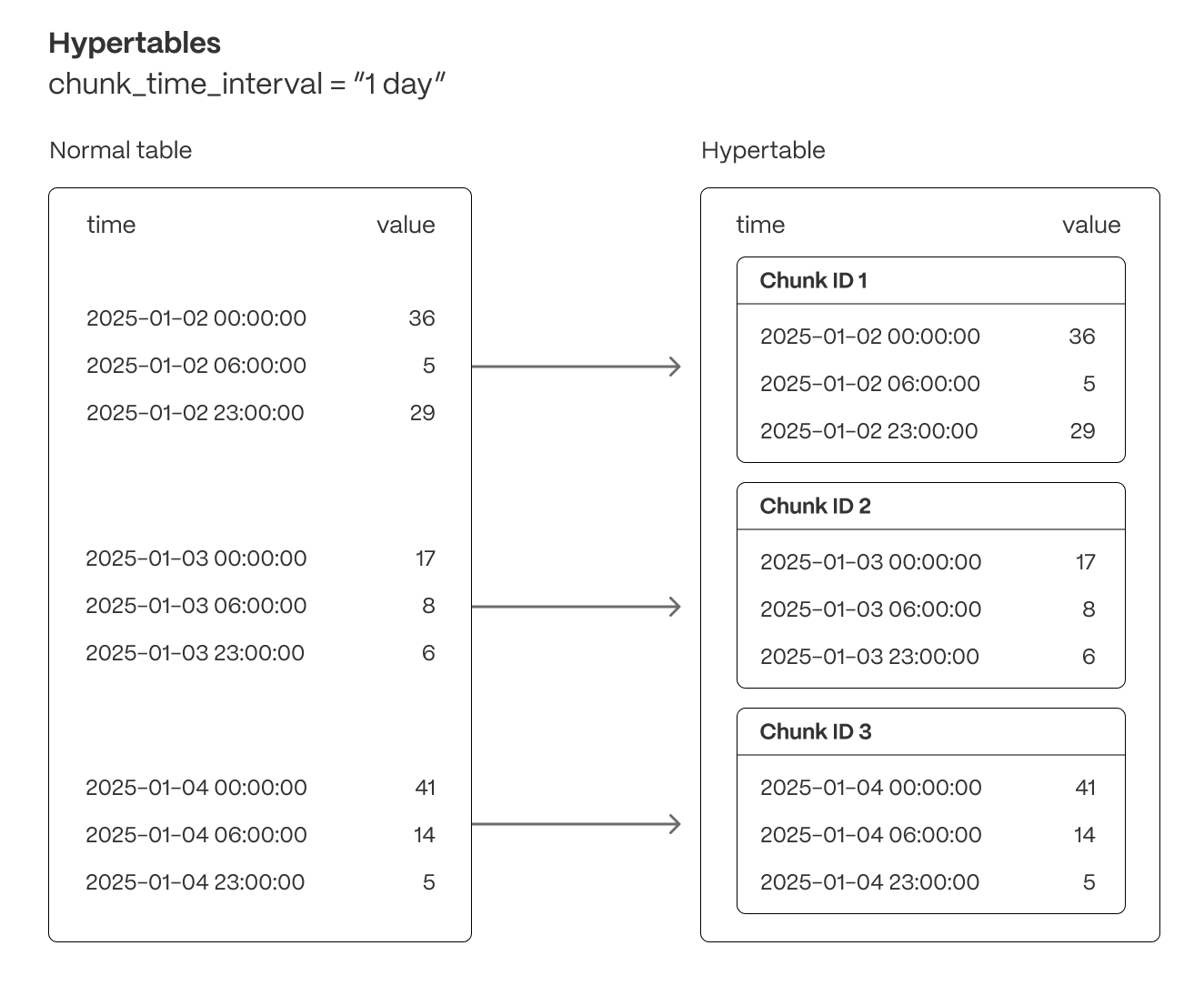
- Efficient data management with automated partitioning by time: splits your data into s that hold data from a specific time range. For example, one day or one week. You can configure this range to better suit your needs.
- Better performance with strategic indexing: an index on time in the descending order is automatically created when you create a hypertable. More indexes are created on the level, to optimize performance. You can create additional indexes, including unique indexes, on the columns you need.
- Faster queries with chunk skipping: skips the s that are irrelevant in the context of your query, dramatically reducing the time and resources needed to fetch results. Even more—you can enable skipping on non-partitioning columns.
- Advanced data analysis with hyperfunctions: enables you to efficiently process, aggregate, and analyze significant volumes of data while maintaining high performance.
Inheritance is not supported for hypertables and may lead to unexpected behavior.
Create a hypertable
To create a for your time-series data, useCREATE TABLE. For efficient queries on data in
the , remember to segmentby the column you will use most often to filter your data. For example:
CREATE TABLE ... WITH ..., the default partitioning column is automatically the first column with a timestamp data type. Also, creates a columnstore policy that automatically converts your data to the , after an interval equal to the value of the chunk_interval, defined through compress_after in the policy. This columnar format enables fast scanning and aggregation, optimizing performance for analytical workloads while also saving significant storage space. In the conversion, s are compressed by up to 98%, and organized for efficient, large-scale queries.
You can customize this policy later using alter_job(). However, to change after or created_before, the compression settings, or the the policy is acting on, you must remove the columnstore policy and add a new one.
You can also manually convert s in a to the .
For v2.23.0 and higher, the table is automatically partitioned on the first column in the table with a timestamp data type. If multiple columns are suitable candidates as a partitioning column, throws an error and asks for an explicit definition. For earlier versions, set
partition_column to a time column.If you are self-hosting v2.20.0 to v2.22.1, to convert your data to the after a specific time interval, you have to call add_columnstore_policy() after you call CREATE TABLE.If you are self-hosting v2.19.3 and below, create a relational table, then convert it using create_hypertable(). You then enable with a call to ALTER TABLE.Samples
Create a hypertable
Create a using theCREATE TABLE syntax with for optimal performance:
Drop old chunks
Remove s older than 3 months to manage storage:View chunk information
Get detailed information about s for a :Add a space dimension
Add a second partitioning dimension for multi-dimensional data:Available functions and commands
Table creation
SQL commands for creating s:CREATE TABLE: create a using standard SQL syntax with
Chunk management
Functions for managing s:show_chunks(): display s associated with sdrop_chunks(): remove s from smove_chunk(): move a to a different tablespacereorder_chunk(): reorder a single by an indexmerge_chunks(): merge multiple s into a singlesplit_chunk(): split a into multiple sattach_chunk(): attach a table as a to adetach_chunk(): detach a from a
Dimension management
Functions for managing dimensions:add_dimension(): add a space-partitioning dimension to aset_chunk_time_interval(): set the time interval for creationset_integer_now_func(): set function to compute current time for integer-based times
Size and statistics
Functions for measuring and sizes:hypertable_size(): get the total disk space used by ahypertable_detailed_size(): get detailed disk space usage for ahypertable_index_size(): get the total size of indexes on ahypertable_approximate_size(): get an approximate total size of ahypertable_approximate_detailed_size(): get approximate detailed size informationchunks_detailed_size(): get detailed size information for s
Tablespace management
Functions for managing tablespaces with s:attach_tablespace(): attach a tablespace to adetach_tablespace(): detach a tablespace from adetach_tablespaces(): detach all tablespaces from ashow_tablespaces(): show tablespaces attached to a
Reordering and policies
Functions for managing reordering:add_reorder_policy(): add a policy to automatically reorder sremove_reorder_policy(): remove an automatic reordering policy
Query optimization
Functions for optimizing queries on s:enable_chunk_skipping(): enable skipping for adisable_chunk_skipping(): disable skipping for a
Legacy functions
For backward compatibility, also providescreate_hypertable(), which was the
original function for creating s. Use CREATE TABLE for new s.