

- A new index type called StreamingDiskANN, inspired by the DiskANN algorithm, based on research from Microsoft.
- Statistical Binary Quantization: developed by Timescale researchers, This compression method improves on standard Binary Quantization.
- Label-based filtered vector search: based on Microsoft’s Filtered DiskANN research, this allows you to combine vector similarity search with label filtering for more precise and efficient results.
pgvector and pgvectorscale achieves 28x lower p95
latency and 16x higher query throughput compared to Pinecone’s storage
optimized (s1) index for approximate nearest neighbor queries at 99% recall,
all at 75% less cost when self-hosted on AWS EC2.
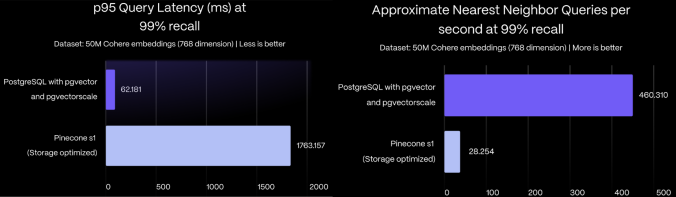 To learn more about the performance impact of pgvectorscale, and details about benchmark methodology and results, see the pgvector vs Pinecone comparison blog post.
In contrast to pgvector, which is written in C, is developed in Rust using the PGRX framework,
offering the community a new avenue for contributing to vector support.
Application developers or DBAs can use with their databases.
If you want to contribute to this extension, see how to build pgvectorscale from source in a developer environment and our testing guide.
For production vector workloads, get private beta access to vector-optimized databases with pgvector and on Timescale. Sign up here for priority access.
To learn more about the performance impact of pgvectorscale, and details about benchmark methodology and results, see the pgvector vs Pinecone comparison blog post.
In contrast to pgvector, which is written in C, is developed in Rust using the PGRX framework,
offering the community a new avenue for contributing to vector support.
Application developers or DBAs can use with their databases.
If you want to contribute to this extension, see how to build pgvectorscale from source in a developer environment and our testing guide.
For production vector workloads, get private beta access to vector-optimized databases with pgvector and on Timescale. Sign up here for priority access.
Installation
The fastest ways to run with are:- Using a pre-built Docker container
- Installing from source
- Enable pgvectorscale in a Timescale Cloud service
Using a pre-built Docker container
- Run the Docker image.
- Connect to your database:
- Create the pgvectorscale extension:
CASCADE automatically installs pgvector.
Installing from source
You can install from source and install it in an existing server[!WARNING] Building pgvectorscale on macOS X86 (Intel) machines is currently not supported due to an open issue. As alternatives, you can:We welcome community contributions to resolve this limitation. If you’re interested in helping, please check the issue for details.
- Use an ARM-based Mac.
- Build using Linux.
- Use our pre-built Docker containers.
- Compile and install the extension
- Connect to your database:
- Ensure the pgvector extension is available:
- Create the pgvectorscale extension:
CASCADE automatically installs pgvector.
Enable pgvectorscale in a Tiger Cloud service
Note: the instructions below are for Timescale’s standard compute instance. For production vector workloads, we’re offering private beta access to vector-optimized databases with pgvector and on Timescale. Sign up here for priority access. To enable :- Create a new Timescale Service.
- Connect to your Timescale service:
- Create the pgvectorscale extension:
CASCADE automatically installs pgvector.
Get started with pgvectorscale
- Create a table with an embedding column. For example:
- Populate the table.
- Create a StreamingDiskANN index on the embedding column:
- Find the 10 closest embeddings using the index.
<=>) queries, for indices created with vector_cosine_ops; L2 distance (<->) queries, for indices created with vector_l2_ops; and inner product (<#>) queries, for indices created with vector_ip_ops. This is the same syntax used by pgvector. If you would like additional distance types,
create an issue. (Note: inner product indices are not compatible with plain storage.)
Filtered Vector Search
supports combining vector similarity search with metadata filtering. There are two basic kinds of filtering, which can be combined in a single query:- Label-based filtering with the diskann index: This provides optimized performance for filtering by labels.
- Arbitrary WHERE clause filtering: This uses post-filtering after the vector search.
Label-based Filtering with diskann
For optimal performance with label filtering, you must specify the label column directly in the index creation:- Create a table with an embedding column and a labels array:
- Create a StreamingDiskANN index on the embedding column, including the labels column:
Note: Label values must be within thesmallintrange (-32768 to 32767). Usingsmallint[]for labels ensures that ‘s type system will automatically enforce these bounds. includes an implementation of the&&overlap operator forsmallint[]arrays, which is used for efficient label-based filtering.
- Perform label-filtered vector searches using the
&&operator (array overlap):
Giving Semantic Meaning to Labels
While the labels must be stored as integers in the array for the index to work efficiently, you can give them semantic meaning by relating them to a separate labels table:- Create a labels table with meaningful descriptions:
- When inserting documents, use the appropriate label IDs:
- When querying, you can join with the labels table to work with meaningful names:
- You can also convert between label names and IDs when filtering:
Arbitrary WHERE Clause Filtering
You can also use any WHERE clause with vector search, but these conditions will be applied as post-filtering:Tuning
The StreamingDiskANN index comes with smart defaults but also the ability to customize its behavior. There are two types of parameters: index build-time parameters that are specified when an index is created and query-time parameters that can be tuned when querying an index. We suggest setting the index build-time paramers for major changes to index operations while query-time parameters can be used to tune the accuracy/performance tradeoff for individual queries. We expect most people to tune the query-time parameters (if any) and leave the index build time parameters set to default.StreamingDiskANN index build-time parameters
The StreamingDiskANN index build process can be memory-intensive. You may need to increase themaintenance_work_mem parameter to improve build performance. For example:
| Parameter name | Description | Default value |
|---|---|---|
storage_layout | memory_optimized which uses SBQ to compress vector data or plain which stores data uncompressed | memory_optimized |
num_neighbors | Sets the maximum number of neighbors per node. Higher values increase accuracy but make the graph traversal slower. | 50 |
search_list_size | This is the S parameter used in the greedy search algorithm used during construction. Higher values improve graph quality at the cost of slower index builds. | 100 |
max_alpha | Is the alpha parameter in the algorithm. Higher values improve graph quality at the cost of slower index builds. | 1.2 |
num_dimensions | The number of dimensions to index. By default, all dimensions are indexed. But you can also index less dimensions to make use of Matryoshka embeddings | 0 (all dimensions) |
num_bits_per_dimension | Number of bits used to encode each dimension when using SBQ | 2 for less than 900 dimensions, 1 otherwise |
num_neighbors parameter is:
StreamingDiskANN query-time parameters
You can also set two parameters to control the accuracy vs. query speed trade-off at query time. We suggest adjustingdiskann.query_rescore to fine-tune accuracy.
| Parameter name | Description | Default value |
|---|---|---|
diskann.query_search_list_size | The number of additional candidates considered during the graph search. | 100 |
diskann.query_rescore | The number of elements rescored (0 to disable rescoring) | 50 |
SET before executing a query. For example:
LOCAL which will
be reset after the end of the transaction:
Null Value Handling
- Null vectors are not indexed
- Null labels are treated as empty arrays
- Null values in label arrays are ignored
ORDER BY vector distance
pgvectorscale’s diskann index uses relaxed ordering which allows results to be slightly out of order by distance. This is analogous to usingiterative scan with relaxed ordering with
pgvector’s ivfflat or hnsw indexes.
If you need strict ordering you can use a materialized CTE: