

Introduction
What is real-time analytics?
Real-time analytics enables applications to process and query data as it is generated and as it accumulates, delivering immediate and ongoing insights for decision-making. Unlike traditional analytics, which relies on batch processing and delayed reporting, real-time analytics supports both instant queries on fresh data and fast exploration of historical trends—powering applications with sub-second query performance across vast, continuously growing datasets. Many modern applications depend on real-time analytics to drive critical functionality:- IoT monitoring systems track sensor data over time, identifying long-term performance patterns while still surfacing anomalies as they arise. This allows businesses to optimize maintenance schedules, reduce costs, and improve reliability.
- Financial and business intelligence platforms analyze both current and historical data to detect trends, assess risk, and uncover opportunities—from tracking stock performance over a day, week, or year to identifying spending patterns across millions of transactions.
- Interactive customer dashboards empower users to explore live and historical data in a seamless experience—whether it’s a SaaS product providing real-time analytics on business operations, a media platform analyzing content engagement, or an e-commerce site surfacing personalized recommendations based on recent and past behavior.
- Low-latency queries ensure sub-second response times even under high load, enabling fast insights for dashboards, monitoring, and alerting.
- Low-latency ingest minimizes the lag between when data is created and when it becomes available for analysis, ensuring fresh and accurate insights.
- Data mutability allows for efficient updates, corrections, and backfills, ensuring analytics reflect the most accurate state of the data.
- Concurrency and scalability enable systems to handle high query volumes and growing workloads without degradation in performance.
- Seamless access to both recent and historical data ensures fast queries across time, whether analyzing live, streaming data, or running deep historical queries on days or months of information.
- Query flexibility provides full SQL support, allowing for complex queries with joins, filters, aggregations, and analytical functions.
: real-time analytics from
is a high-performance database that brings real-time analytics to applications. It combines fast queries, high ingest performance, and full SQL support—all while ensuring scalability and reliability. extends with the extension. It enables sub-second queries on vast amounts of incoming data while providing optimizations designed for continuously updating datasets. achieves this through the following optimizations:- Efficient data partitioning: automatically and transparently partitioning data into chunks, ensuring fast queries, minimal indexing overhead, and seamless scalability
- Row-columnar storage: providing the flexibility of a row store for transactions and the performance of a column store for analytics
- **Optimized query execution: **using techniques like chunk and batch exclusion, columnar storage, and vectorized execution to minimize latency
- Continuous aggregates: precomputing analytical results for fast insights without expensive reprocessing
- **Cloud-native operation: **compute/compute separation, elastic usage-based storage, horizontal scale out, data tiering to object storage
- **Operational simplicity: **offering high availability, connection pooling, and automated backups for reliable and scalable real-time applications
Data model
Today’s applications demand a database that can handle real-time analytics and transactional queries without sacrificing speed, flexibility, or SQL compatibility (including joins between tables). achieves this with hypertables, which provide an automatic partitioning engine, and hypercore, a hybrid row-columnar storage engine designed to deliver high-performance queries and efficient compression (up to 95%) within .Efficient data partitioning
provides hypertables, a table abstraction that automatically partitions data into chunks in real time (using time stamps or incrementing IDs) to ensure fast queries and predictable performance as datasets grow. Unlike traditional relational databases that require manual partitioning, hypertables automate all aspects of partition management, keeping locking minimal even under high ingest load. At ingest time, hypertables ensure that can deal with a constant stream of data without suffering from table bloat and index degradation by automatically partitioning data across time. Because each chunk is ordered by time and has its own indexes and storage, writes are usually isolated to small, recent chunks—keeping index sizes small, improving cache locality, and reducing the overhead of vacuum and background maintenance operations. This localized write pattern minimizes write amplification and ensures consistently high ingest performance, even as total data volume grows. At query time, hypertables efficiently exclude irrelevant chunks from the execution plan when the partitioning column is used in aWHERE clause. This architecture ensures fast query execution, avoiding the gradual slowdowns that affect non-partitioned tables as they accumulate millions of rows. Chunk-local indexes keep indexing overhead minimal, ensuring index operations scans remain efficient regardless of dataset size.
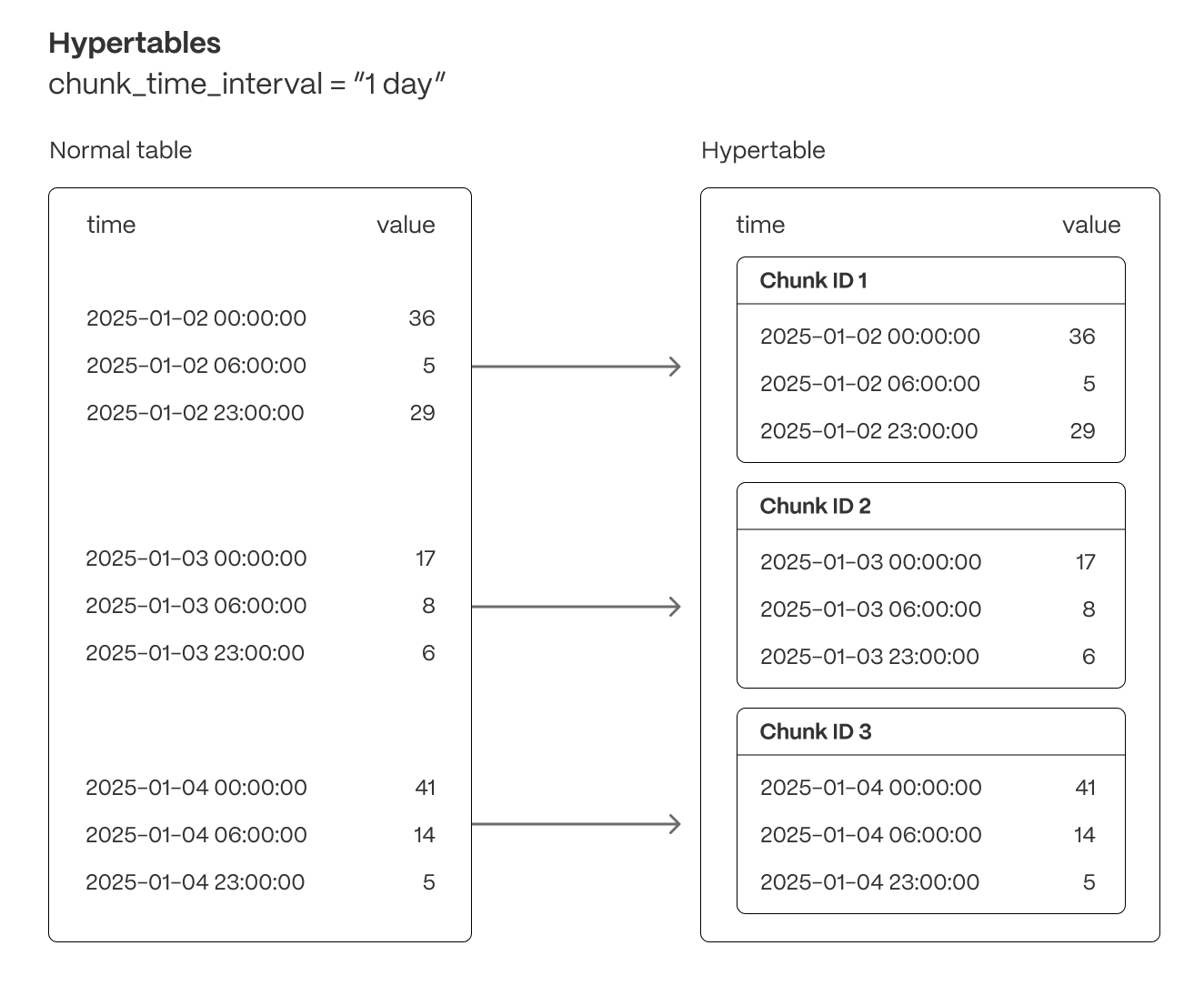 Hypertables are the foundation for all of ’s real-time analytics capabilities. They enable seamless data ingestion, high-throughput writes, optimized query execution, and chunk-based lifecycle management—including automated data retention (drop a chunk) and data tiering (move a chunk to object storage).
Hypertables are the foundation for all of ’s real-time analytics capabilities. They enable seamless data ingestion, high-throughput writes, optimized query execution, and chunk-based lifecycle management—including automated data retention (drop a chunk) and data tiering (move a chunk to object storage).
Row-columnar storage
Traditional databases force a trade-off between fast inserts (row-based storage) and efficient analytics (columnar storage). Hypercore eliminates this trade-off, allowing real-time analytics without sacrificing transactional capabilities. Hypercore dynamically stores data in the most efficient format for its lifecycle:- Row-based storage for recent data: the most recent chunk (and possibly more) is always stored in the rowstore, ensuring fast inserts, updates, and low-latency single record queries. Additionally, row-based storage is used as a writethrough for inserts and updates to columnar storage.
- Columnar storage for analytical performance: chunks are automatically compressed into the columnstore, optimizing storage efficiency and accelerating analytical queries.
Columnar storage layout
’s columnar storage layout optimizes analytical query performance by structuring data efficiently on disk, reducing scan times, and maximizing compression rates. Unlike traditional row-based storage, where data is stored sequentially by row, columnar storage organizes and compresses data by column, allowing queries to retrieve only the necessary fields in batches rather than scanning entire rows. But unlike many column store implementations, ’s columnstore supports full mutability—inserts, upserts, updates, and deletes, even at the individual record level—with transactional guarantees. Data is also immediately visible to queries as soon as it is written.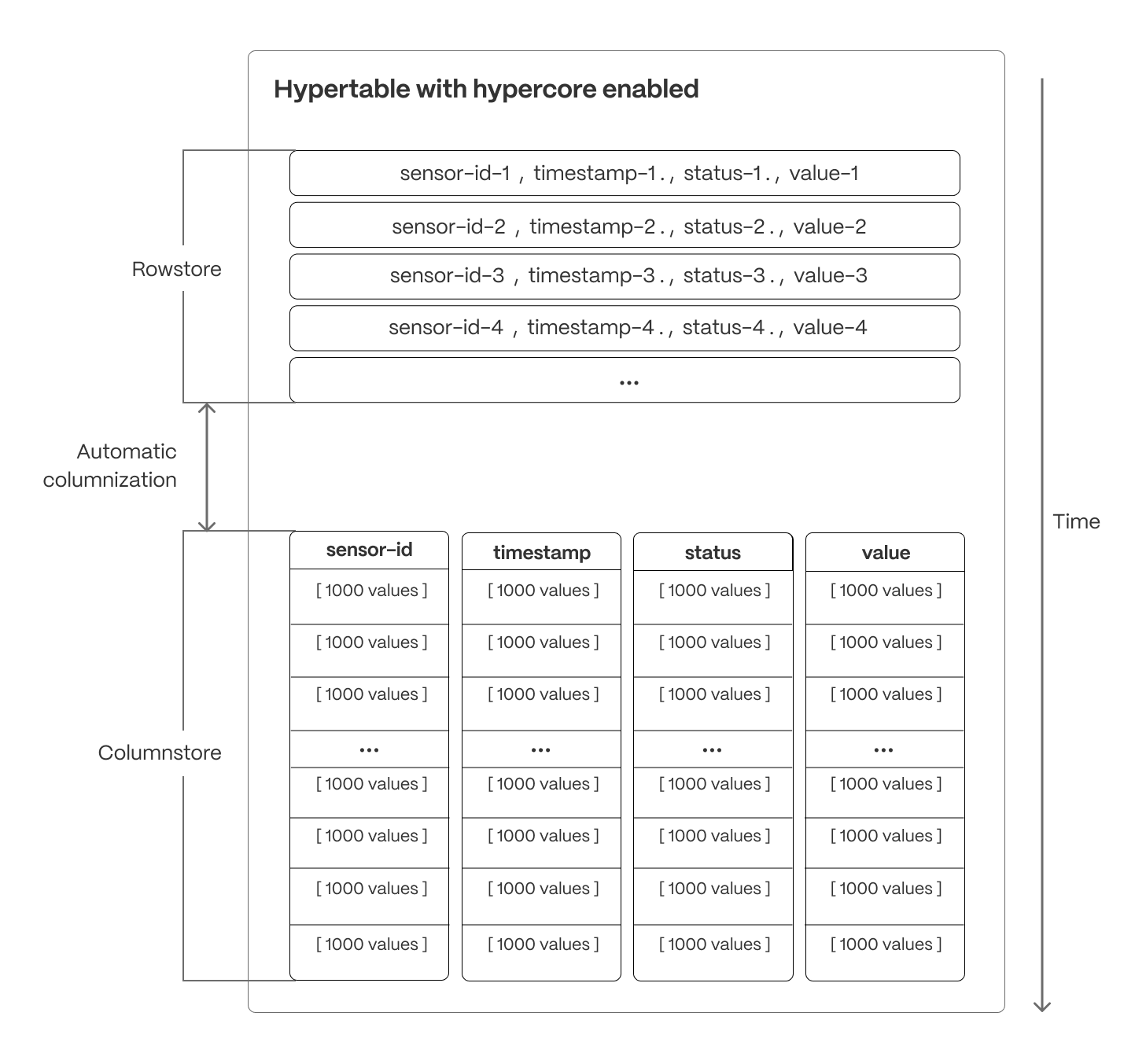
Columnar batches
uses columnar collocation and columnar compression within row-based storage to optimize analytical query performance while maintaining full compatibility. This approach ensures efficient storage, high compression ratios, and rapid query execution.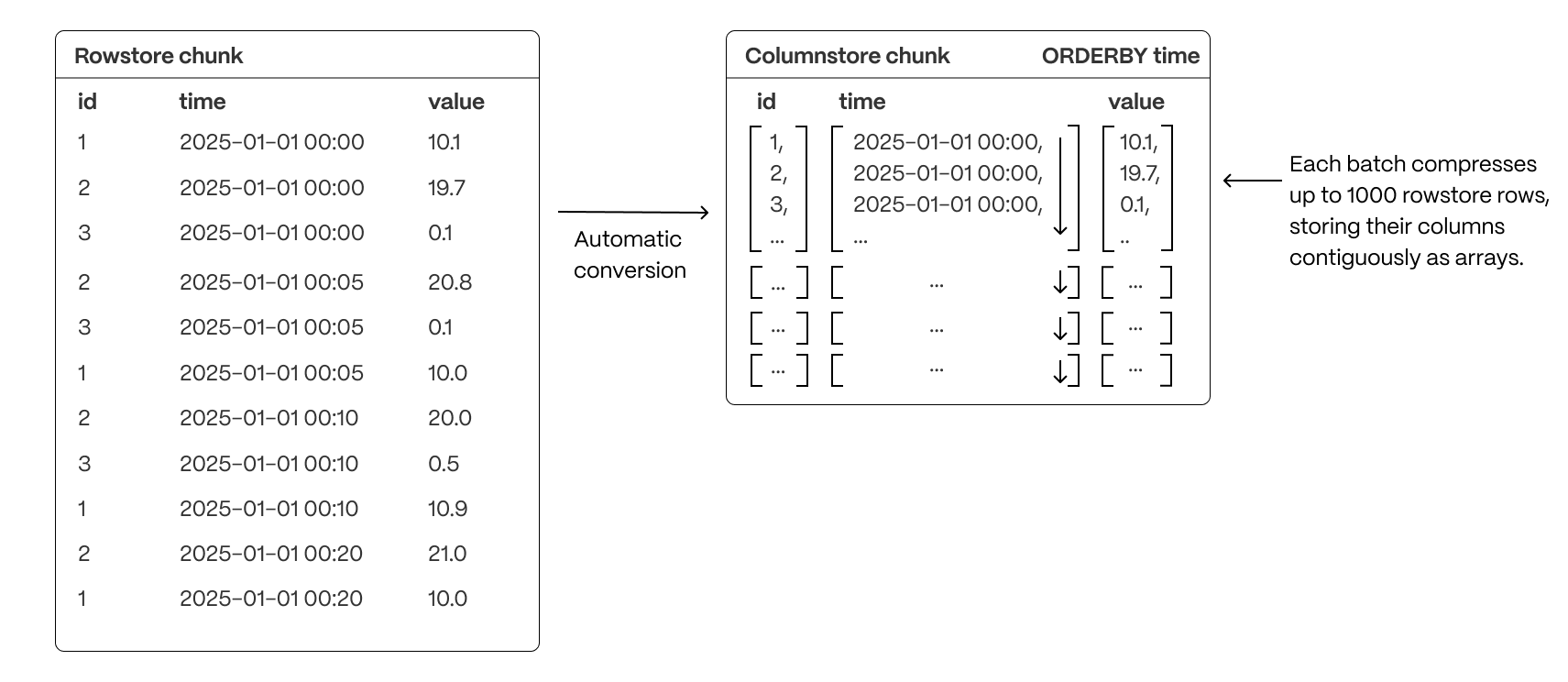 A rowstore chunk is converted to a columnstore chunk by successfully grouping together sets of rows (typically up to 1000) into a single batch, then converting the batch into columnar form.
Each compressed batch does the following:
A rowstore chunk is converted to a columnstore chunk by successfully grouping together sets of rows (typically up to 1000) into a single batch, then converting the batch into columnar form.
Each compressed batch does the following:
- Encapsulates columnar data in compressed arrays of up to 1,000 values per column, stored as a single entry in the underlying compressed table
- Uses a column-major format within the batch, enabling efficient scans by co-locating values of the same column and allowing the selection of individual columns without reading the entire batch
- Applies advanced compression techniques at the column level, including run-length encoding, delta encoding, and Gorilla compression, to significantly reduce storage footprint (by up to 95%) and improve I/O performance.
Segmenting and ordering data
To optimize query performance, allows explicit control over how data is physically organized within columnar storage. By structuring data effectively, queries can minimize disk reads and execute more efficiently, using vectorized execution for parallel batch processing where possible.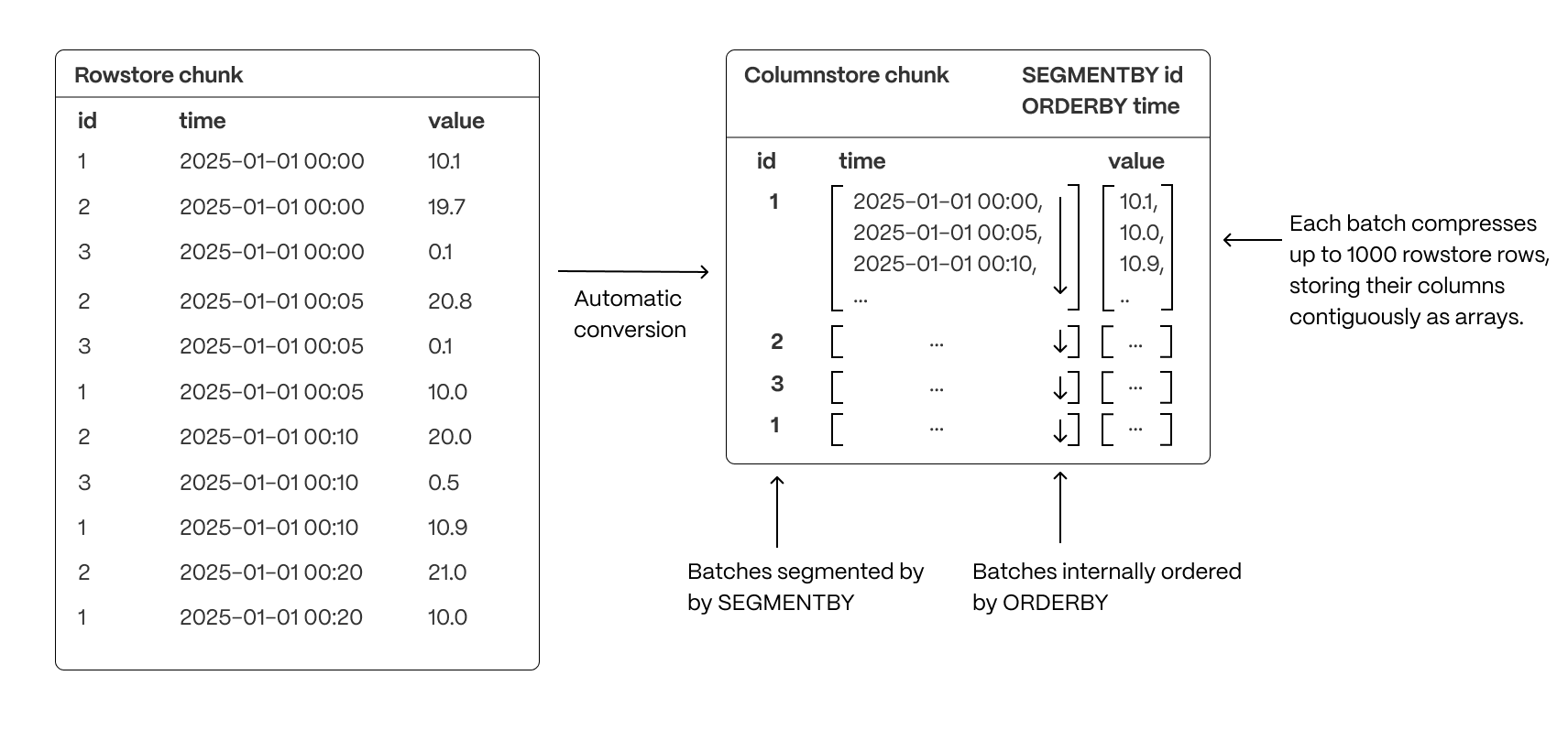
- Group related data together to improve scan efficiency: organizing rows into logical segments ensures that queries filtering by a specific value only scan relevant data sections. For example, in the above, querying for a specific ID is particularly fast. (Implemented with
SEGMENTBY.) - Sort data within segments to accelerate range queries: defining a consistent order reduces the need for post-query sorting, making time-based queries and range scans more efficient. (Implemented with
ORDERBY.) - Reduce disk reads and maximize vectorized execution: a well-structured storage layout enables efficient batch processing (Single Instruction, Multiple Data, or SIMD vectorization) and parallel execution, optimizing query performance.
Data mutability
Traditional databases force a trade-off between fast updates and efficient analytics. Fully immutable storage is impractical in real-world applications, where data needs to change. Asynchronous mutability—where updates only become visible after batch processing—introduces delays that break real-time workflows. In-place mutability, while theoretically ideal, is prohibitively slow in columnar storage, requiring costly decompression, segmentation, ordering, and recompression cycles. Hypercore navigates these trade-offs with a hybrid approach that enables immediate updates without modifying compressed columnstore data in place. By staging changes in an interim rowstore chunk, hypercore allows updates and deletes to happen efficiently while preserving the analytical performance of columnar storage.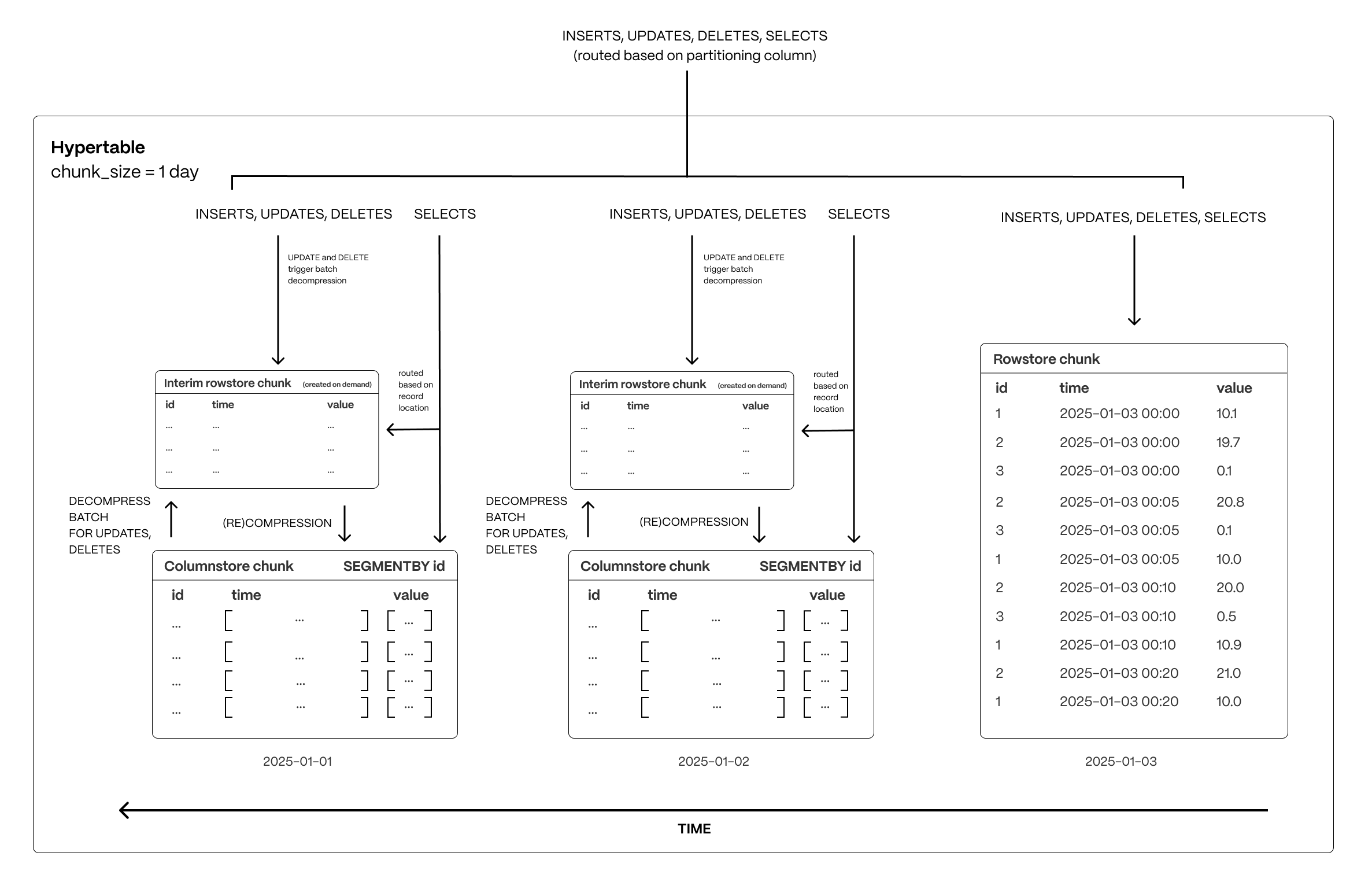
Real-time writes without delays
All new data which is destined for a columnstore chunk is first written to an interim rowstore chunk, ensuring high-speed ingestion and immediate queryability. Unlike fully columnar systems that require ingestion to go through compression pipelines, hypercore allows fresh data to remain in a fast row-based structure before being later compressed into columnar format in ordered batches as normal. Queries transparently access both the rowstore and columnstore chunks, meaning applications always see the latest data instantly, regardless of its storage format.Efficient updates and deletes without performance penalties
When modifying or deleting existing data, hypercore avoids the inefficiencies of both asynchronous updates and in-place modifications. Instead of modifying compressed storage directly, affected batches are decompressed and staged in the interim rowstore chunk, where changes are applied immediately. These modified batches remain in row storage until they are recompressed and reintegrated into the columnstore (which happens automatically via a background process). This approach ensures updates are immediately visible, but without the expensive overhead of decompressing and rewriting entire chunks. This approach avoids:- The rigidity of immutable storage, which requires workarounds like versioning or copy-on-write strategies
- The delays of asynchronous updates, where modified data is only visible after batch processing
- The performance hit of in-place mutability, which makes compressed storage prohibitively slow for frequent updates
- The restrictions some databases have on not altering the segmentation or ordering keys
Query optimizations
Real-time analytics isn’t just about raw speed—it’s about executing queries efficiently, reducing unnecessary work, and maximizing performance. optimizes every step of the query lifecycle to ensure that queries scan only what’s necessary, make use of data locality, and execute in parallel for sub-second response times over large datasets.Skip unnecessary data
minimizes the amount of data a query touches, reducing I/O and improving execution speed:Primary partition exclusion (row and columnar)
Queries automatically skip irrelevant partitions (chunks) based on the primary partitioning key (usually a timestamp), ensuring they only scan relevant data.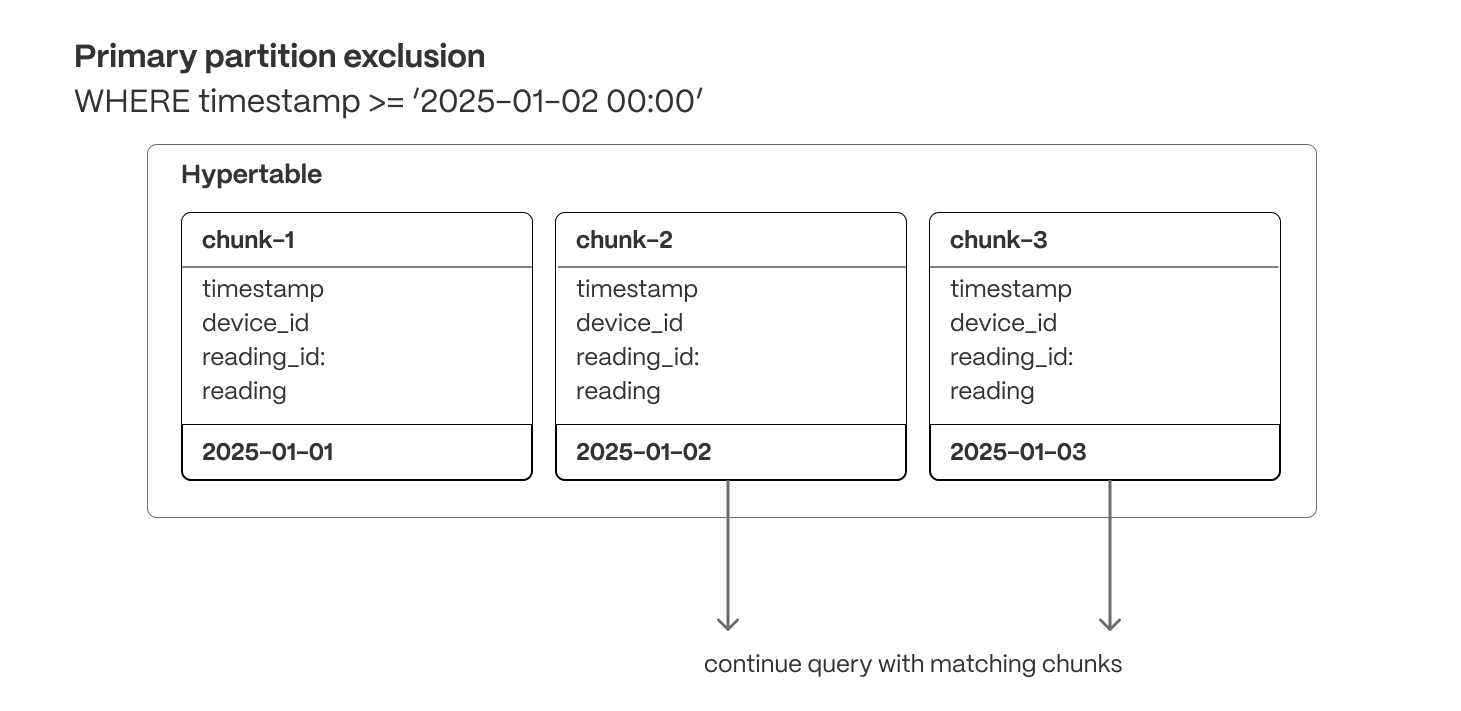
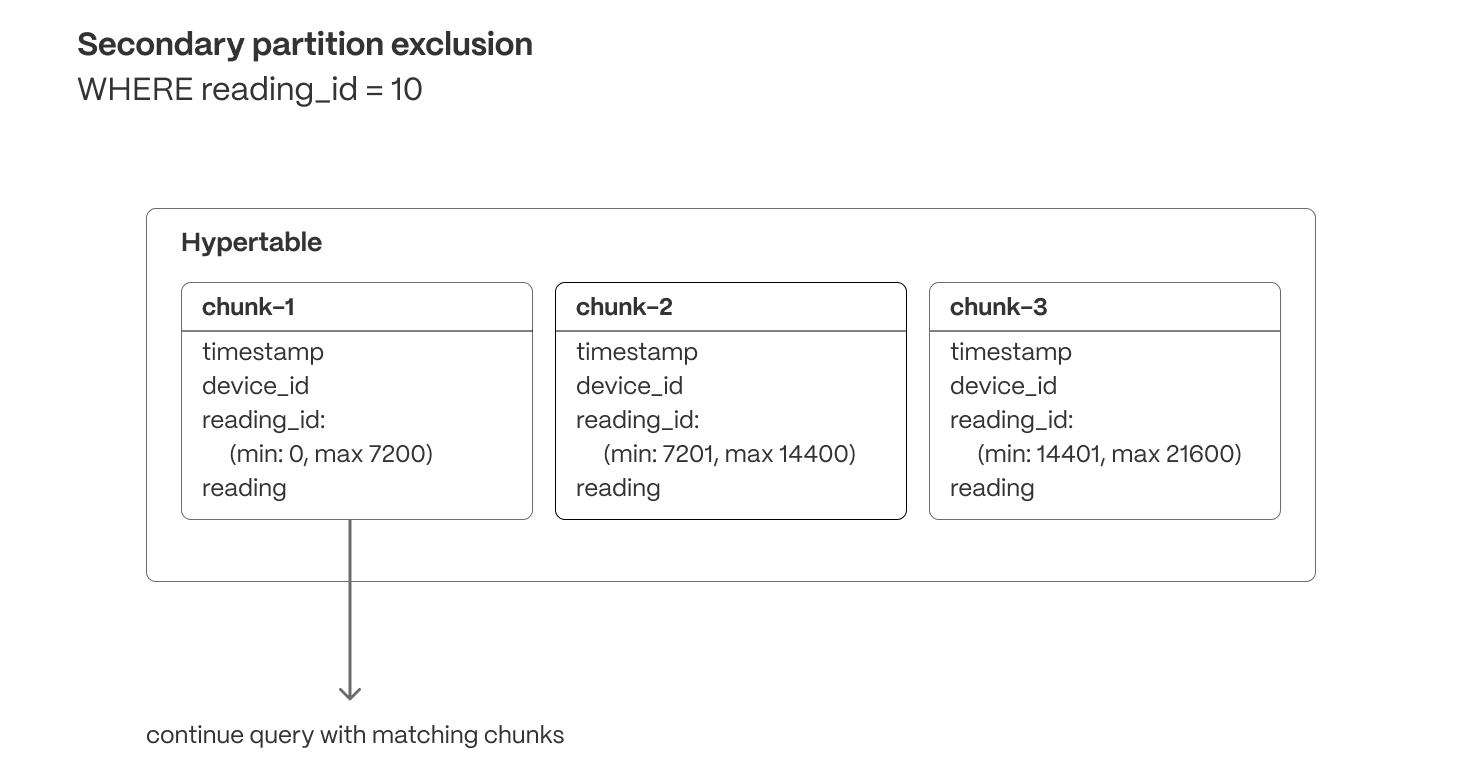
Secondary partition exclusion (columnar)
Min/max metadata allows queries filtering on correlated dimensions (e.g.,order_id or secondary timestamps) to exclude chunks that don’t contain relevant data.
indexes (row and columnar)
Unlike many databases, supports standard indexes on columnstore data (B-tree and hash currently, when using the hypercore table access method), allowing queries to efficiently locate specific values within both row-based and compressed columnar storage. These indexes enable fast lookups, range queries, and filtering operations that further reduce unnecessary data scans.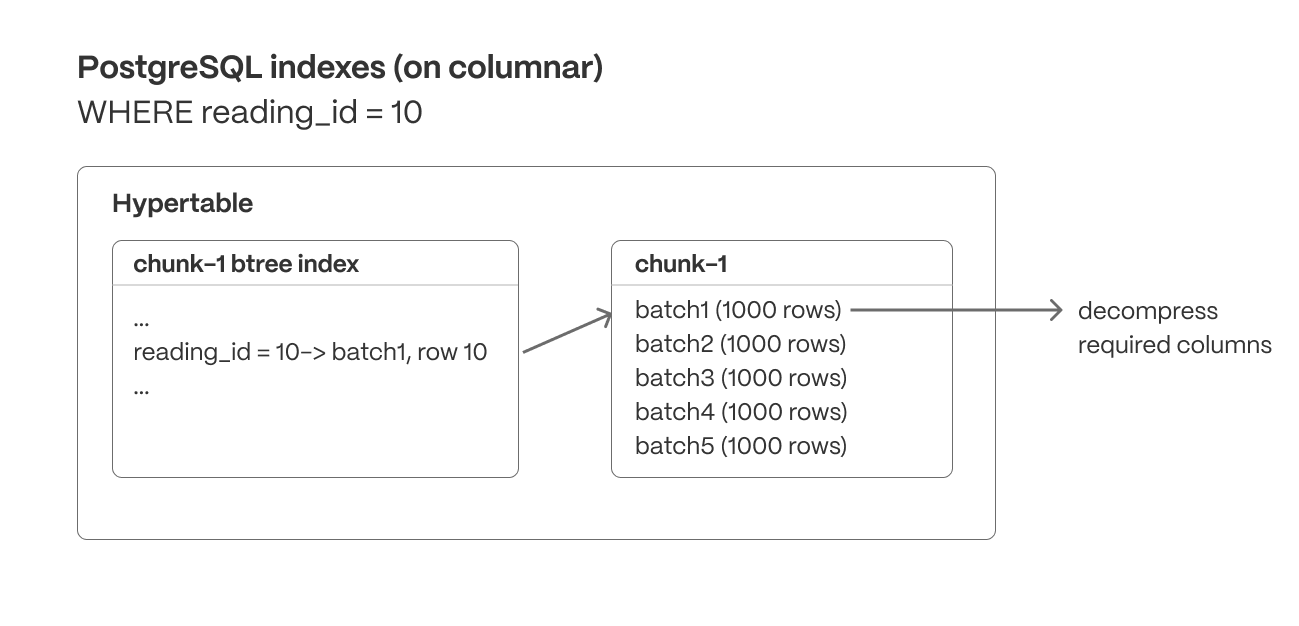
Batch-level filtering (columnar)
Within each chunk, compressed columnar batches are organized usingSEGMENTBY keys and ordered by ORDERBY columns. Indexes and min/max metadata can be used to quickly exclude batches that don’t match the query criteria.
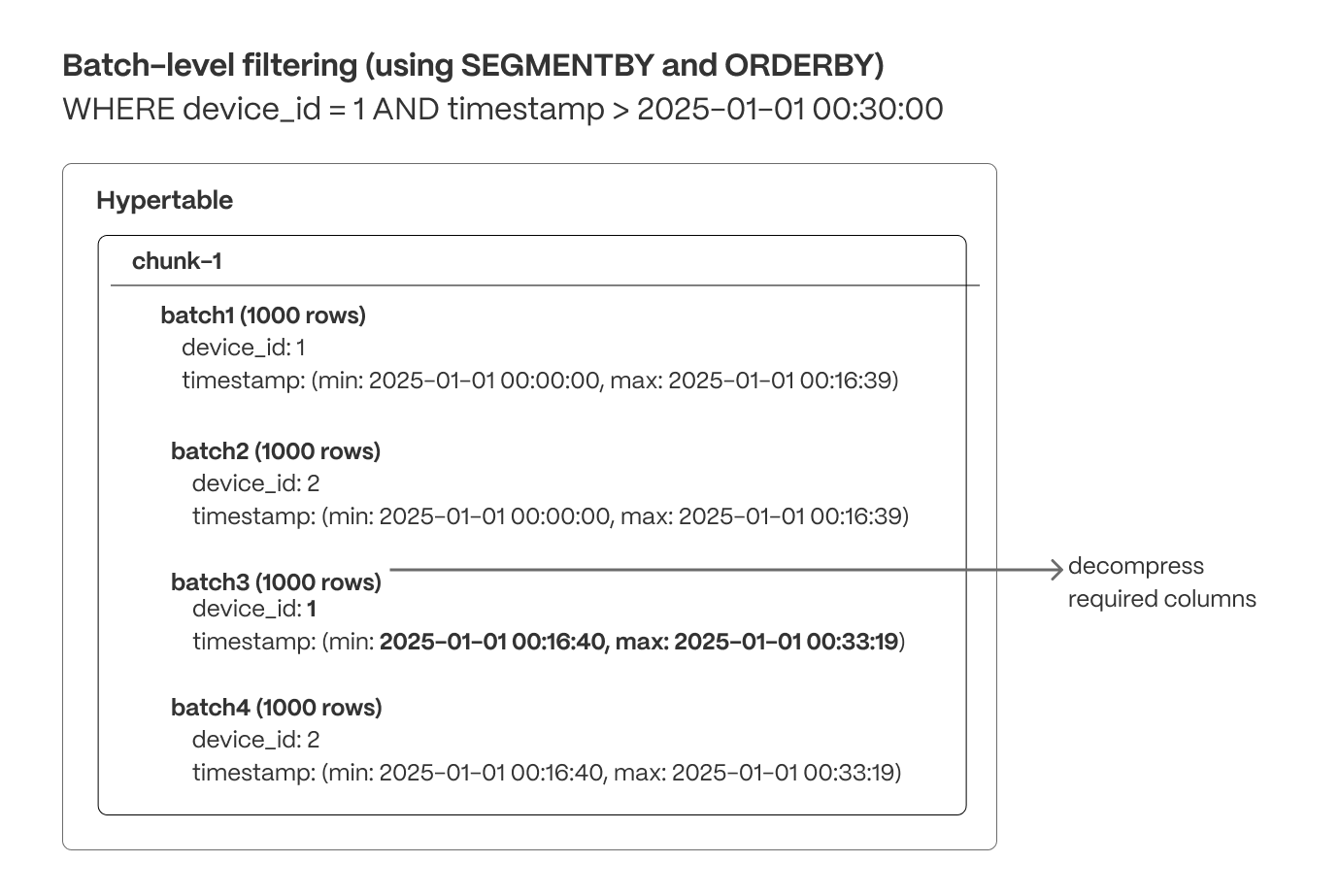
Maximize locality
Organizing data for efficient access ensures queries are read in the most optimal order, reducing unnecessary random reads and reducing scans of unneeded data.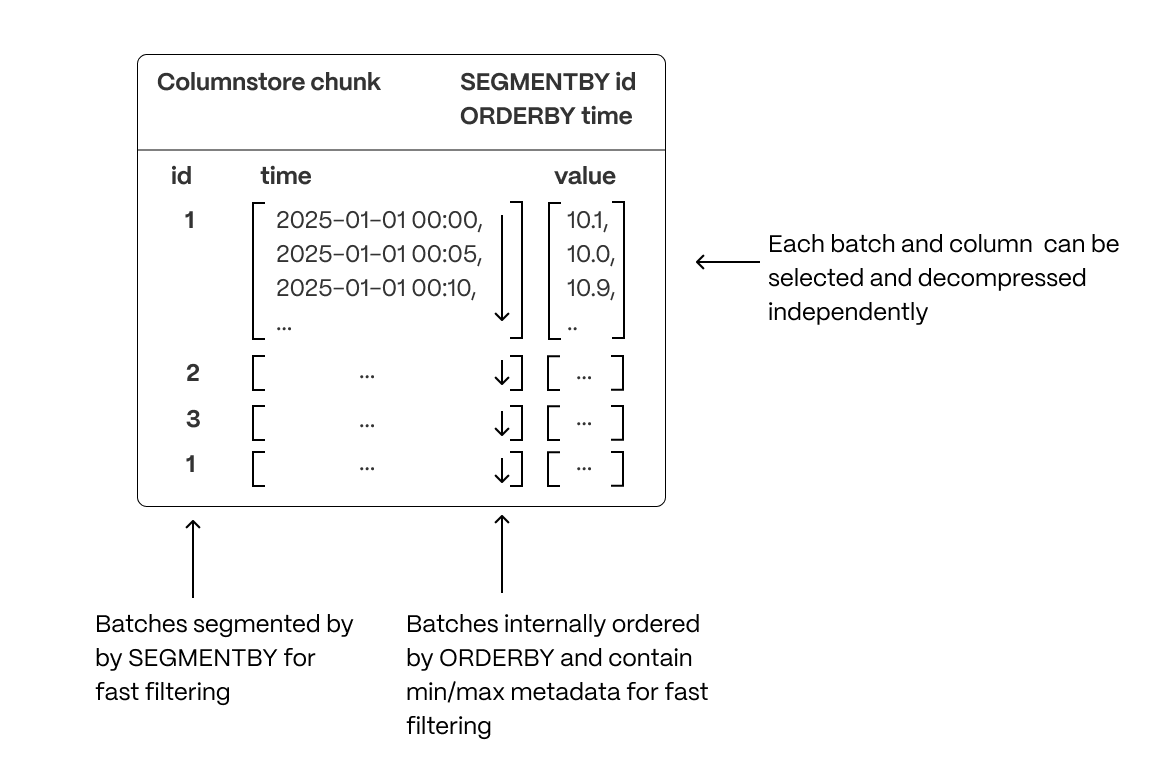
- Segmentation: Columnar batches are grouped using
SEGMENTBYto keep related data together, improving scan efficiency. - Ordering: Data within each batch is physically sorted using
ORDERBY, increasing scan efficiency (and reducing I/O operations), enabling efficient range queries, and minimizing post-query sorting. - Column selection: Queries read only the necessary columns, reducing disk I/O, decompression overhead, and memory usage.
Parallelize execution
Once a query is scanning only the required columnar data in the optimal order, is able to maximize performance through parallel execution. As well as using multiple workers, accelerates columnstore query execution by using Single Instruction, Multiple Data (SIMD) vectorization, allowing modern CPUs to process multiple data points in parallel.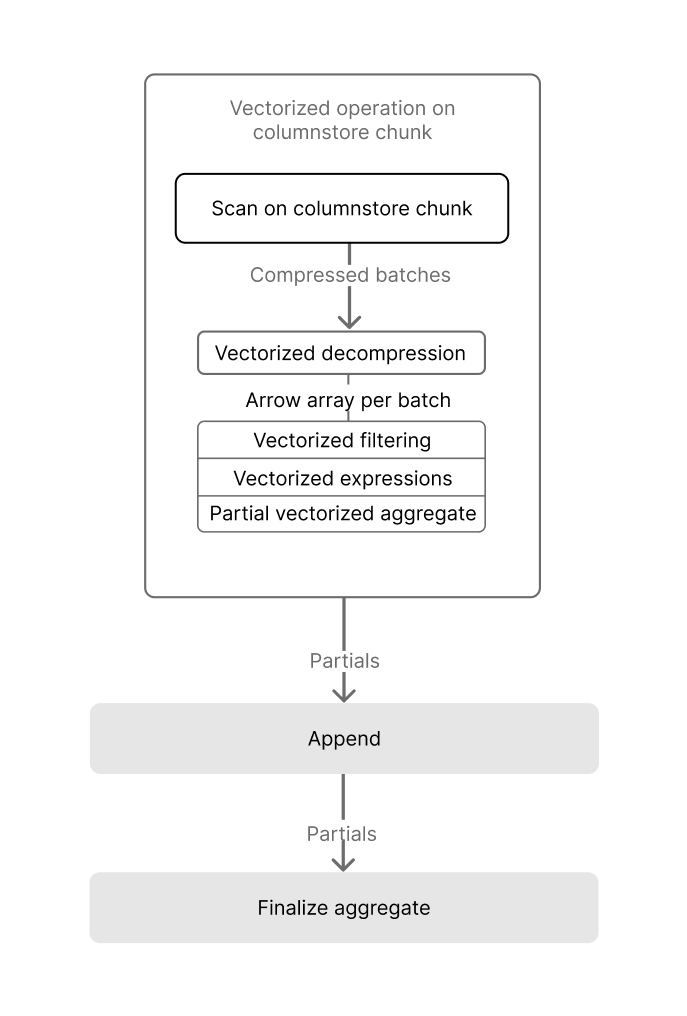 The implementation of SIMD vectorization currently allows:
The implementation of SIMD vectorization currently allows:
- Vectorized decompression, which efficiently restores compressed data into a usable form for analysis.
- Vectorized filtering, which rapidly applies filter conditions across data sets.
- Vectorized aggregation, which performs aggregate calculations, such as sum or average, across multiple data points concurrently.
Accelerating queries with continuous aggregates
Aggregating large datasets in real time can be expensive, requiring repeated scans and calculations that strain CPU and I/O. While some databases attempt to brute-force these queries at runtime, compute and I/O are always finite resources—leading to high latency, unpredictable performance, and growing infrastructure costs as data volume increases. Continuous aggregates, the implementation of incrementally updated materialized views, solve this by shifting computation from every query run to a single, asynchronous step after data is ingested. Only the time buckets that receive new or modified data are updated, and queries read precomputed results instead of scanning raw data—dramatically improving performance and efficiency.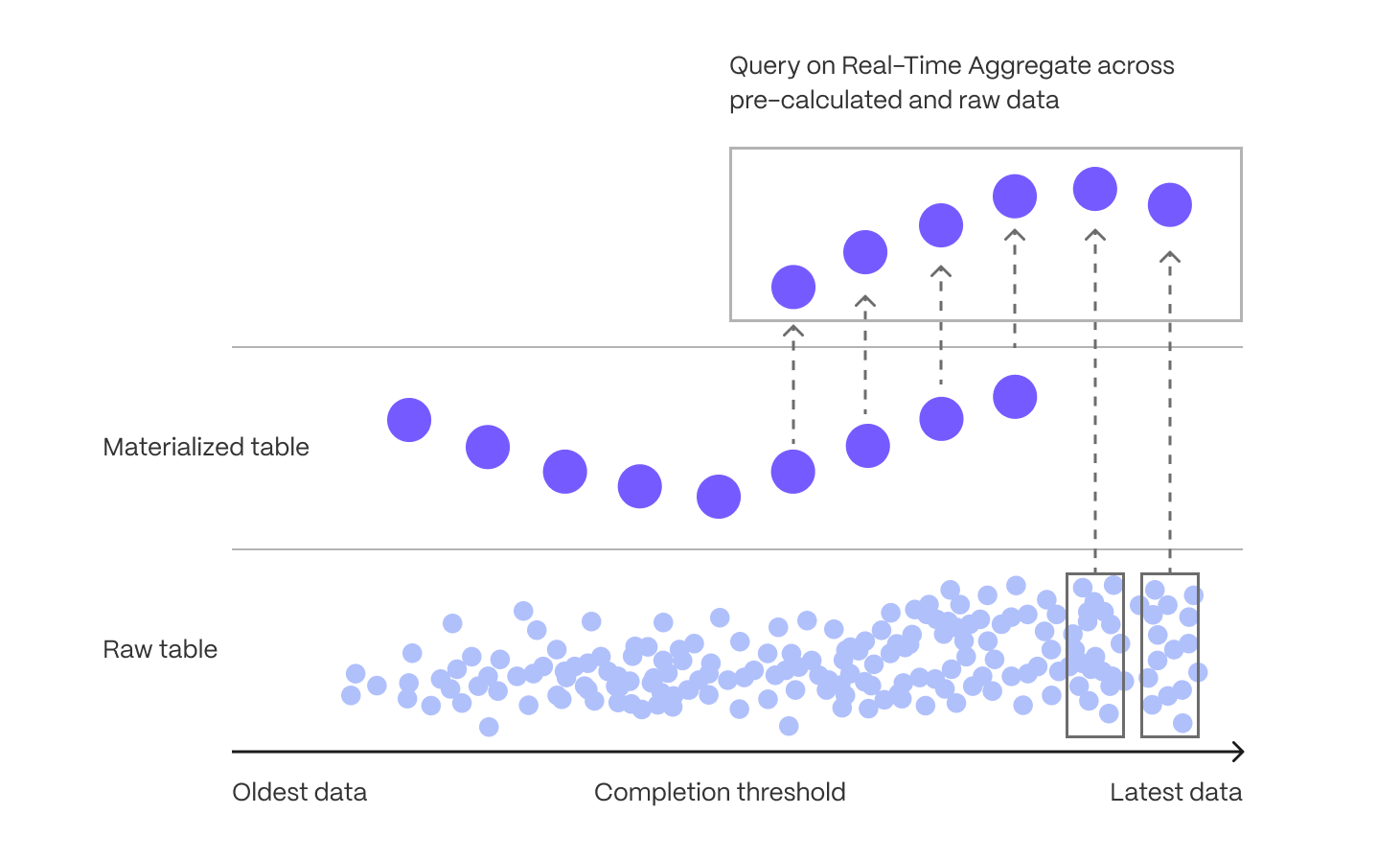 When you know the types of queries you’ll need ahead of time, continuous aggregates allow you to pre-aggregate data along meaningful time intervals—such as per-minute, hourly, or daily summaries—delivering instant results without on-the-fly computation.
Continuous aggregates also avoid the time-consuming and error-prone process of maintaining manual rollups, while continuing to offer data mutability to support efficient updates, corrections, and backfills. Whenever new data is inserted or modified in chunks which have been materialized, stores invalidation records reflecting that these results are stale and need to be recomputed. Then, an asynchronous process re-computes regions that include invalidated data, and updates the materialized results. tracks the lineage and dependencies between continuous aggregates and their underlying data, to ensure the continuous aggregates are regularly kept up-to-date. This happens in a resource-efficient manner, and where multiple invalidations can be coalesced into a single refresh (as opposed to refreshing any dependencies at write time, such as via a trigger-based approach).
Continuous aggregates themselves are stored in hypertables, and they can be converted to columnar storage for compression, and raw data can be dropped, reducing storage footprint and processing cost. Continuous aggregates also support hierarchical rollups (e.g., hourly to daily to monthly) and real-time mode, which merges precomputed results with the latest ingested data to ensure accurate, up-to-date analytics.
This architecture enables scalable, low-latency analytics while keeping resource usage predictable—ideal for dashboards, monitoring systems, and any workload with known query patterns.
When you know the types of queries you’ll need ahead of time, continuous aggregates allow you to pre-aggregate data along meaningful time intervals—such as per-minute, hourly, or daily summaries—delivering instant results without on-the-fly computation.
Continuous aggregates also avoid the time-consuming and error-prone process of maintaining manual rollups, while continuing to offer data mutability to support efficient updates, corrections, and backfills. Whenever new data is inserted or modified in chunks which have been materialized, stores invalidation records reflecting that these results are stale and need to be recomputed. Then, an asynchronous process re-computes regions that include invalidated data, and updates the materialized results. tracks the lineage and dependencies between continuous aggregates and their underlying data, to ensure the continuous aggregates are regularly kept up-to-date. This happens in a resource-efficient manner, and where multiple invalidations can be coalesced into a single refresh (as opposed to refreshing any dependencies at write time, such as via a trigger-based approach).
Continuous aggregates themselves are stored in hypertables, and they can be converted to columnar storage for compression, and raw data can be dropped, reducing storage footprint and processing cost. Continuous aggregates also support hierarchical rollups (e.g., hourly to daily to monthly) and real-time mode, which merges precomputed results with the latest ingested data to ensure accurate, up-to-date analytics.
This architecture enables scalable, low-latency analytics while keeping resource usage predictable—ideal for dashboards, monitoring systems, and any workload with known query patterns.
Hyperfunctions for real-time analytics
Real-time analytics requires more than basic SQL functions—efficient computation is essential as datasets grow in size and complexity. Hyperfunctions, available through thetimescaledb_toolkit extension, provide high-performance, SQL-native functions tailored for time-series analysis. These include advanced tools for gap-filling, percentile estimation, time-weighted averages, counter correction, and state tracking, among others.
A key innovation of hyperfunctions is their support for partial aggregation, which allows to store intermediate computational states rather than just final results. These partials can later be merged to compute rollups efficiently, avoiding expensive reprocessing of raw data and reducing compute overhead. This is especially effective when combined with continuous aggregates.
Consider a real-world example: monitoring request latencies across thousands of application instances. You might want to compute p95 latency per minute, then roll that up into hourly and daily percentiles for dashboards or alerts. With traditional SQL, calculating percentiles requires a full scan and sort of all underlying data—making multi-level rollups computationally expensive.
With , you can use the percentile_agg hyperfunction in a continuous aggregate to compute and store a partial aggregation state for each minute. This state efficiently summarizes the distribution of latencies for that time bucket, without storing or sorting all individual values. Later, to produce an hourly or daily percentile, you simply combine the stored partials—no need to reprocess the raw latency values.
This approach provides a scalable, efficient solution for percentile-based analytics. By combining hyperfunctions with continuous aggregates, enables real-time systems to deliver fast, resource-efficient insights across high-ingest, high-resolution datasets—without sacrificing accuracy or flexibility.